⏱️ ~16 นาที
📊 18 sections
📹 คอร์สติ๊กต๊อก 2026
📋 Overview
บทเรียนนี้สอนใช้ Workflow Dashboard V1 — เว็บแอปที่รวม 3 workflow อัตโนมัติไว้ในหน้าเดียว ครอบคลุมตั้งแต่ดึง subtitle จาก YouTube, ถอดเสียง VDO ด้วย faster-whisper, จับภาพ screenshot ด้วย ffmpeg, สร้าง HTML presentation (Blue Template) จนถึงสร้างเสียงพากย์ด้วย Ai TTS ทั้ง gTTS และ tts.lnwsj.com พร้อมรวมเป็นวิดีโอคู่มือสำเร็จรูป สรุป 18 จุดสำคัญ
🗂️ สารบัญ
1) แนะนำ Workflow Dashboard V1
📍 00:00:00
"รวม 3 workflow อัตโนมัติไว้ในที่เดียว — กดคัดลอกคำสั่งแล้วรันได้เลย"
 📸 หน้าแรก Workflow Dashboard แสดง Hero + 3 tabs สำหรับเลือก workflow
📸 หน้าแรก Workflow Dashboard แสดง Hero + 3 tabs สำหรับเลือก workflow
⚡ ภาพรวม Dashboard
- Workflow Dashboard V1 เป็น standalone web app (HTML/CSS/JS) — ไม่ต้องติดตั้ง framework ไม่ต้องรัน server
- เปิดใช้งาน:
open WorkflowAppV1/index.html — ทำงานได้ทันทีบน browser
- แบ่งเป็น 3 tabs หลัก: YouTube Pipeline, Manual Recording, TTS Script Gen
- ทุก step มี ปุ่ม 📋 Copy กดคัดลอกคำสั่งไปรันใน terminal ได้เลย ไม่ต้องจำ
- ออกแบบ Dark Theme + glassmorphism cards + smooth animations — ดูง่าย สวยงาม
- มีส่วน Quick Reference ด้านล่าง — รวมเครื่องมือทั้งหมดไว้จุดเดียว
- 💡 Responsive design ใช้ได้ทั้ง PC, Tablet, และมือถือ
2) โครงสร้างหน้า Dashboard
📍 00:00:53
"Navbar ด้านบน มี 4 ลิงก์ กดกระโดดไปส่วนต่างๆ ได้ทันที"
 📸 Navbar + Hero section แสดง title VDO → Subtitle → Presentation → TTS
📸 Navbar + Hero section แสดง title VDO → Subtitle → Presentation → TTS
🖥️ ส่วนประกอบหน้าจอ
- Navbar ด้านบน: 4 ลิงก์ — YouTube, Manual, TTS, Reference กดแล้ว smooth scroll
- Hero ตรงกลาง: แสดงชื่อ Workflow Dashboard พร้อมคำอธิบาย "รวม 3 workflow ไว้ในที่เดียว"
- ใต้ Hero มี 3 tab buttons: กดสลับระหว่าง YouTube Pipeline / Manual Recording / TTS
- tab ที่ active จะ เรืองแสงสีม่วง — บอกได้ทันทีว่ากำลังดูอะไร
- แต่ละ tab มี step cards เรียงตามลำดับ — ทำตามจากบนลงล่าง
- ด้านล่างสุดมี Quick Reference grid — ลิสต์เครื่องมือที่ต้องติดตั้ง
- 💡 กดปุ่ม 📚 Reference ใน navbar จะกระโดดไปเครื่องมือทันที
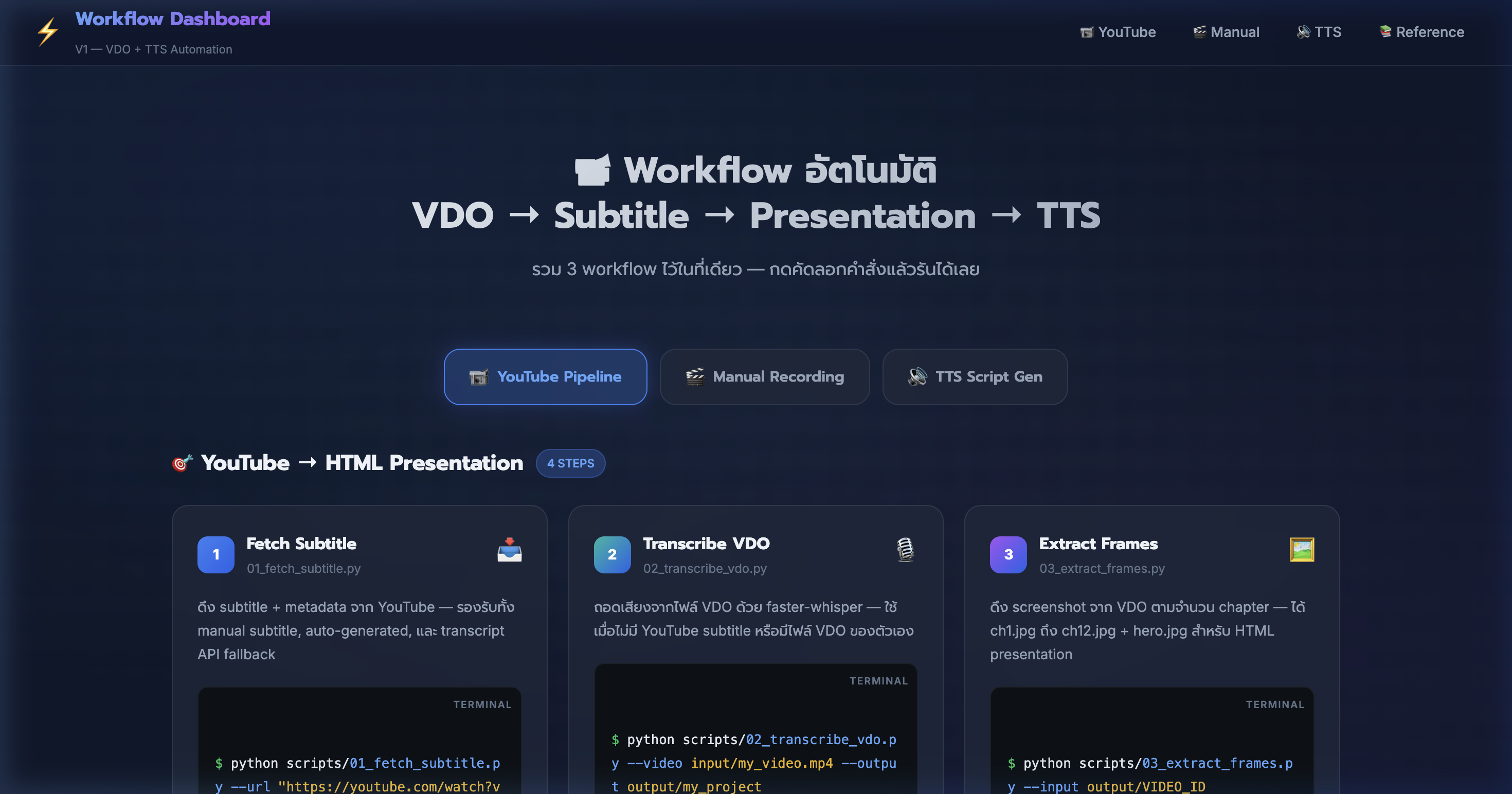
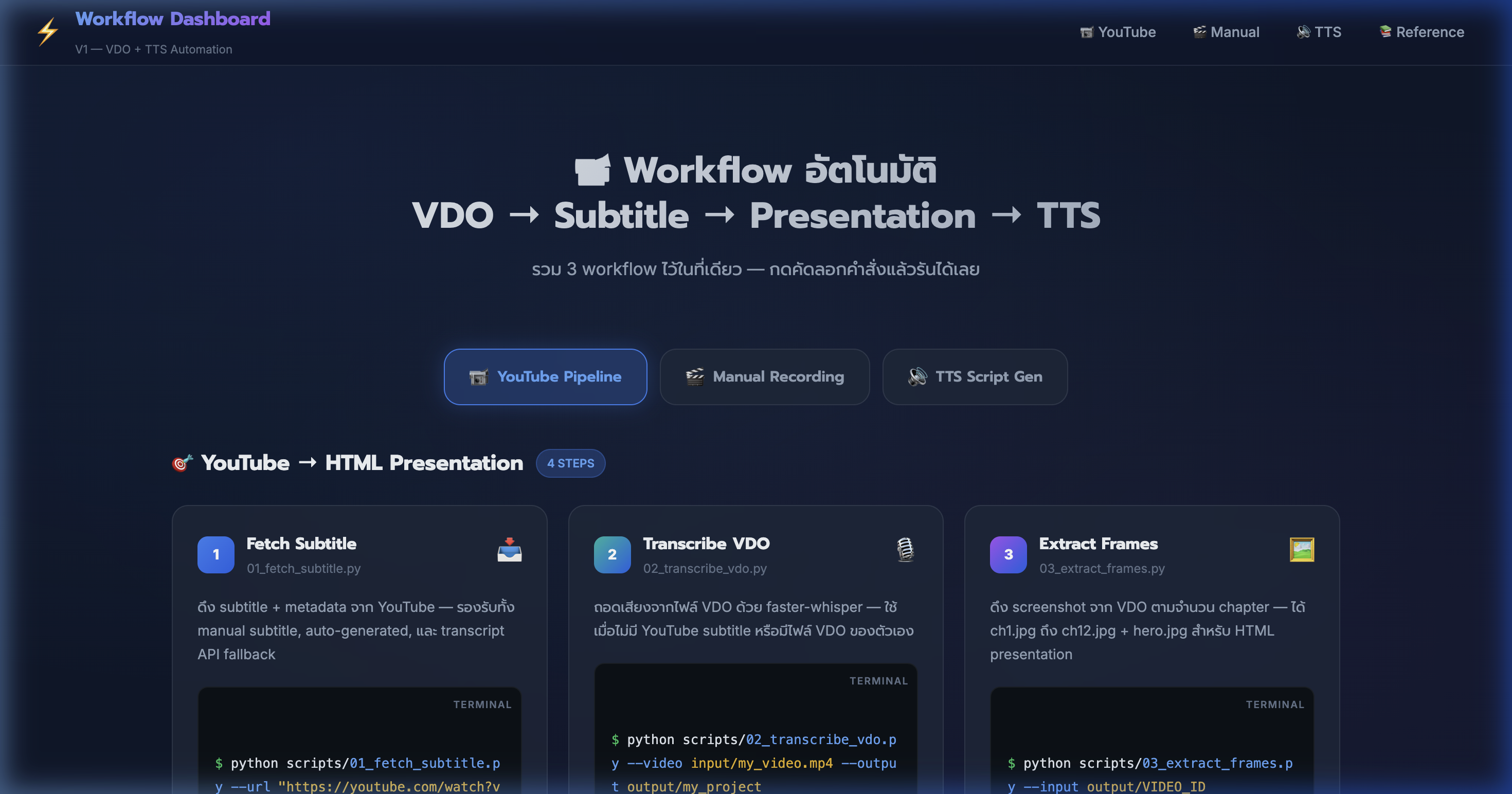
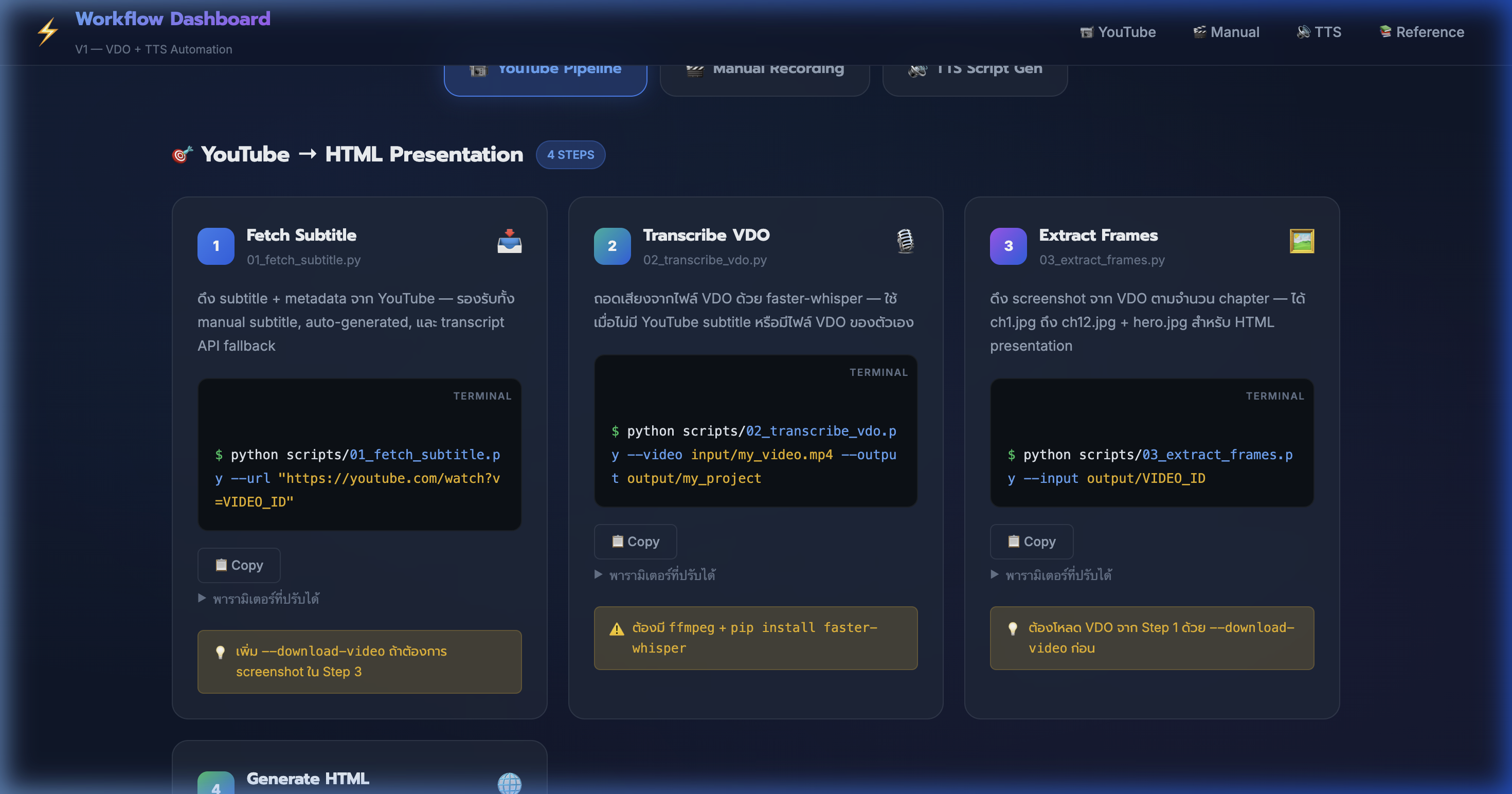
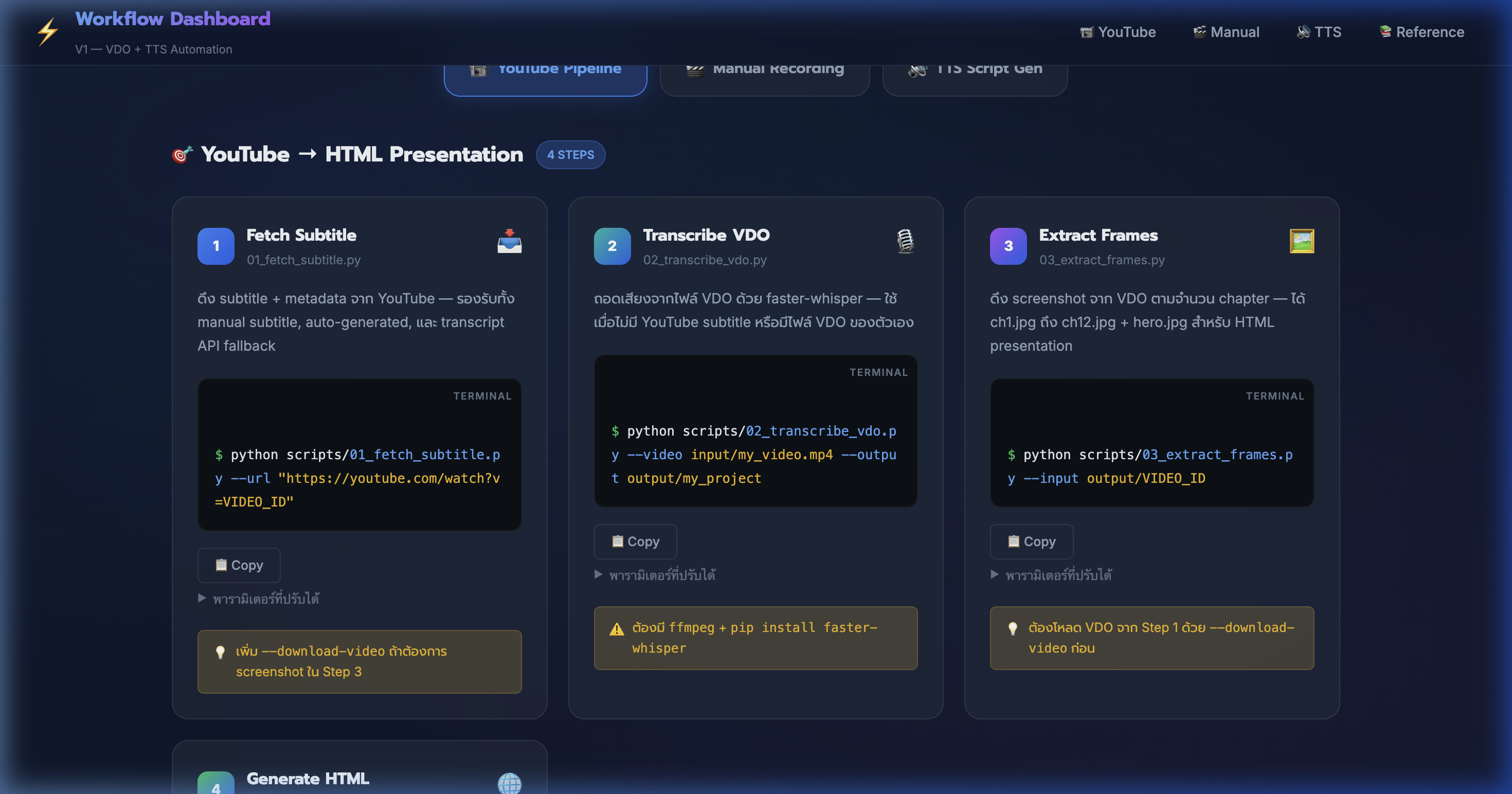
3) Tab 1: YouTube Pipeline — ดึง Subtitle
📍 00:01:46
"ดึง subtitle + metadata จาก YouTube — รองรับทั้ง manual subtitle, auto-generated, และ transcript API fallback"
 📸 YouTube Pipeline tab — Step 1: Fetch Subtitle ด้วย 01_fetch_subtitle.py
📸 YouTube Pipeline tab — Step 1: Fetch Subtitle ด้วย 01_fetch_subtitle.py
📥 Step 1: Fetch Subtitle
- ใช้สคริปต์
python scripts/01_fetch_subtitle.py --url "YouTube URL"
- ระบบลองดึง manual subtitle ภาษาไทยก่อน → ถ้าไม่มีดึง auto-generated
- ถ้าทั้ง 2 ไม่มี → ใช้ youtube-transcript-api เป็น fallback อัตโนมัติ
- เพิ่ม
--download-video ถ้าต้องการ โหลด VDO มาจับภาพด้วย
- ผลลัพธ์:
output/VIDEO_ID/metadata.json + subtitle.th.vtt
- ระบบใช้ yt-dlp ซึ่งรองรับ YouTube, Facebook, TikTok และอีกหลายเว็บ
- 💡 กดปุ่ม 📋 Copy ใน Dashboard จะได้คำสั่งพร้อม placeholder — แค่เปลี่ยน URL
4) YouTube Pipeline — ถอดเสียง VDO
📍 00:02:39
"ถอดเสียงจากไฟล์ VDO ด้วย faster-whisper — ได้ subtitle คุณภาพสูง"
 📸 Step 2: Transcribe VDO ด้วย 02_transcribe_vdo.py + model options
📸 Step 2: Transcribe VDO ด้วย 02_transcribe_vdo.py + model options
🎙️ Step 2: Transcribe VDO
- ใช้สคริปต์
python scripts/02_transcribe_vdo.py --video input/my_video.mp4
- ใช้ faster-whisper — AI ถอดเสียงภาษาไทยแม่นยำระดับ 90%+
- เลือก model ได้: tiny (เร็ว ไม่แม่น) → base (สมดุล) → large-v3 (แม่นสุด ช้า)
- เหมาะกับ VDO ที่ ไม่มีบน YouTube หรือต้องการ subtitle คุณภาพสูงของเรา
- ระบบแยกเสียงจาก VDO ด้วย
ffmpeg → audio.wav → ถอดเสียง → .vtt
- ติดตั้ง:
pip install faster-whisper (ต้องมี Python 3.8+ และ ffmpeg)
- ⚠️ model large-v3 ใช้ RAM ~6 GB → PC เก่าแนะนำ base หรือ small
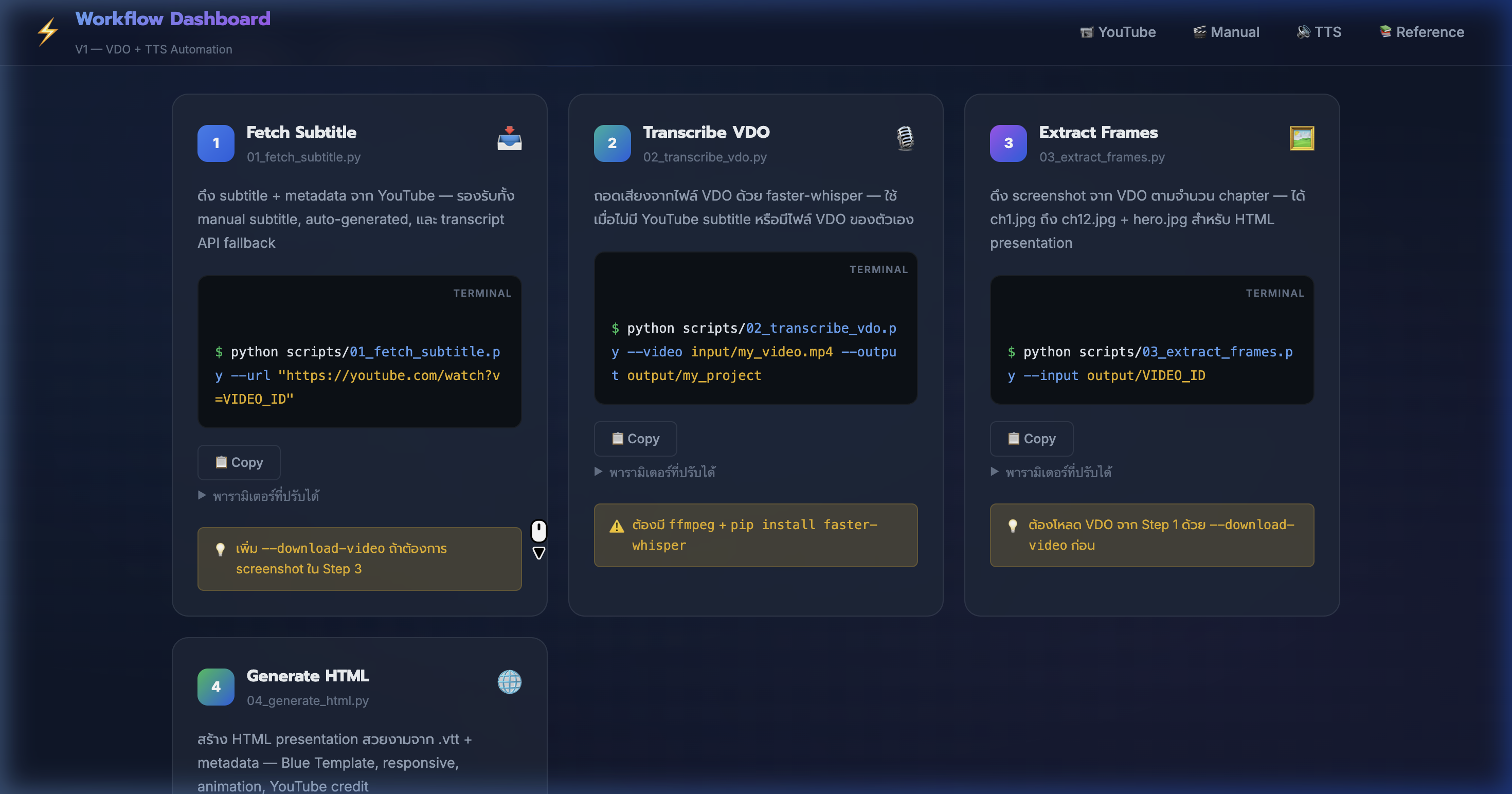
5) YouTube Pipeline — ดึง Screenshot
📍 00:03:32
"ดึง screenshot จาก VDO ตามจำนวน chapter — ได้ ch1.jpg ถึง ch12.jpg + hero.jpg"
 📸 Step 3: Extract Frames ด้วย 03_extract_frames.py + parameter table
📸 Step 3: Extract Frames ด้วย 03_extract_frames.py + parameter table
🖼️ Step 3: Extract Frames
- ใช้สคริปต์
python scripts/03_extract_frames.py --input output/VIDEO_ID
- ระบบอ่าน .vtt หาตำแหน่ง timestamp ของแต่ละ chapter → จับภาพ ณ จุดนั้น
- ผลลัพธ์:
frames/ch1.jpg ถึง ch12.jpg + hero.jpg (ปก)
- ปรับจำนวน chapter ได้:
--chapters 8 หรือ --chapters 18
- ใช้ ffmpeg จับภาพด้วย
-vframes 1 -q:v 2 → คุณภาพสูง ไฟล์เล็ก
- hero.jpg จับที่วินาทีที่ 10 → ได้ภาพแรกของ VDO ที่ไม่ใช่จอดำ
- 💡 ถ้าไม่มี VDO → ข้ามขั้นตอนนี้ได้ HTML จะแสดงโดยไม่มีภาพ
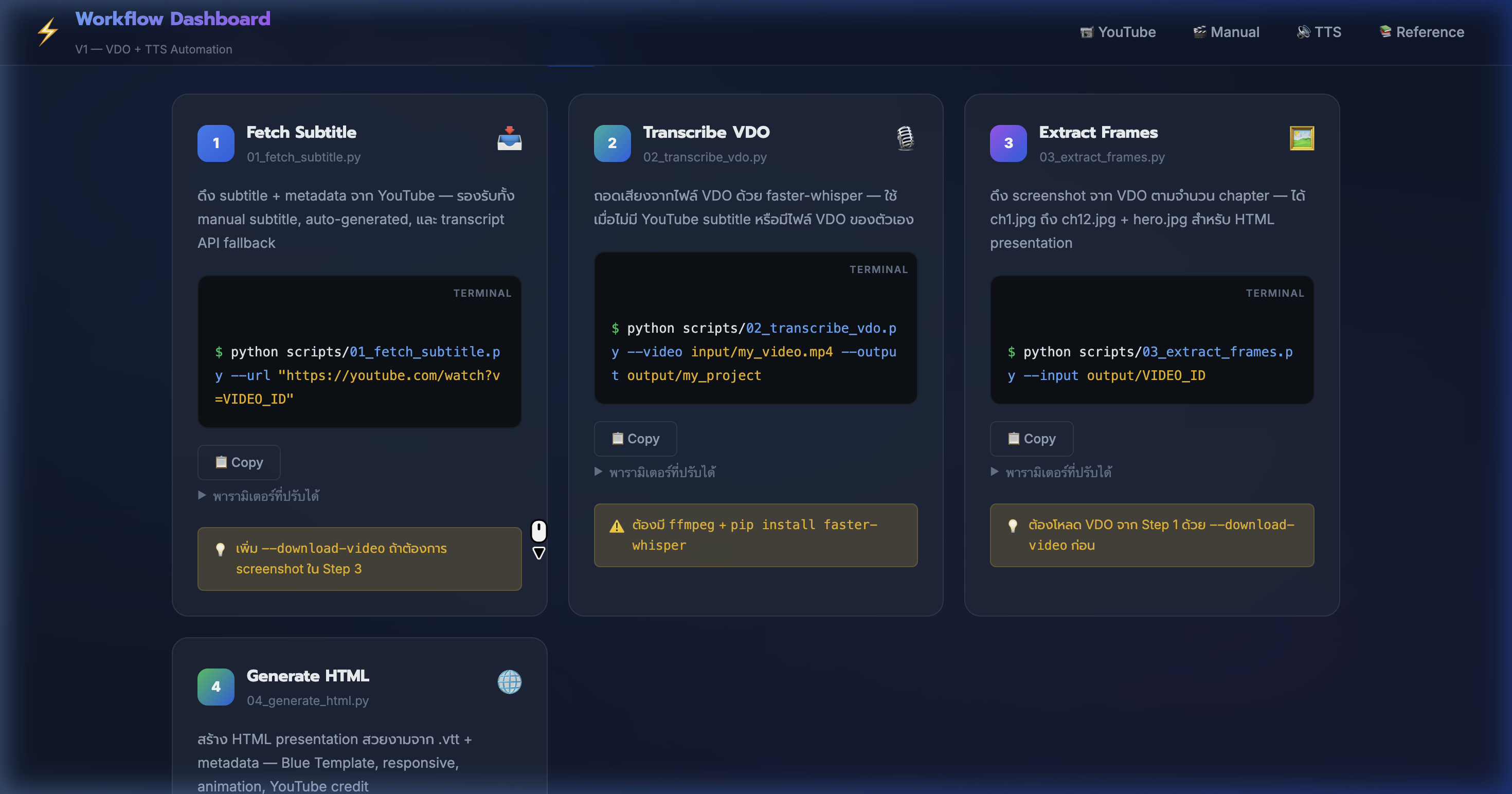
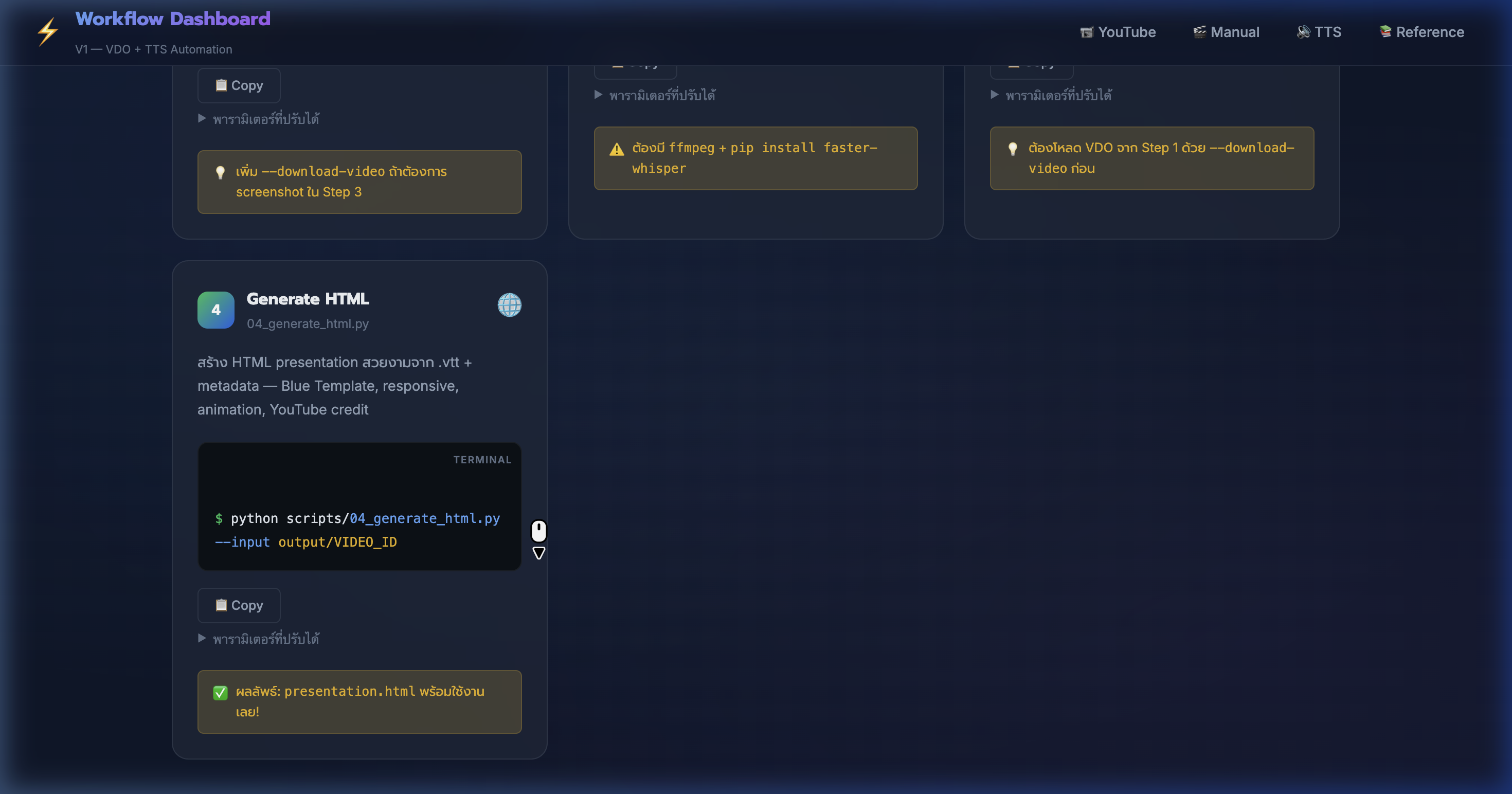
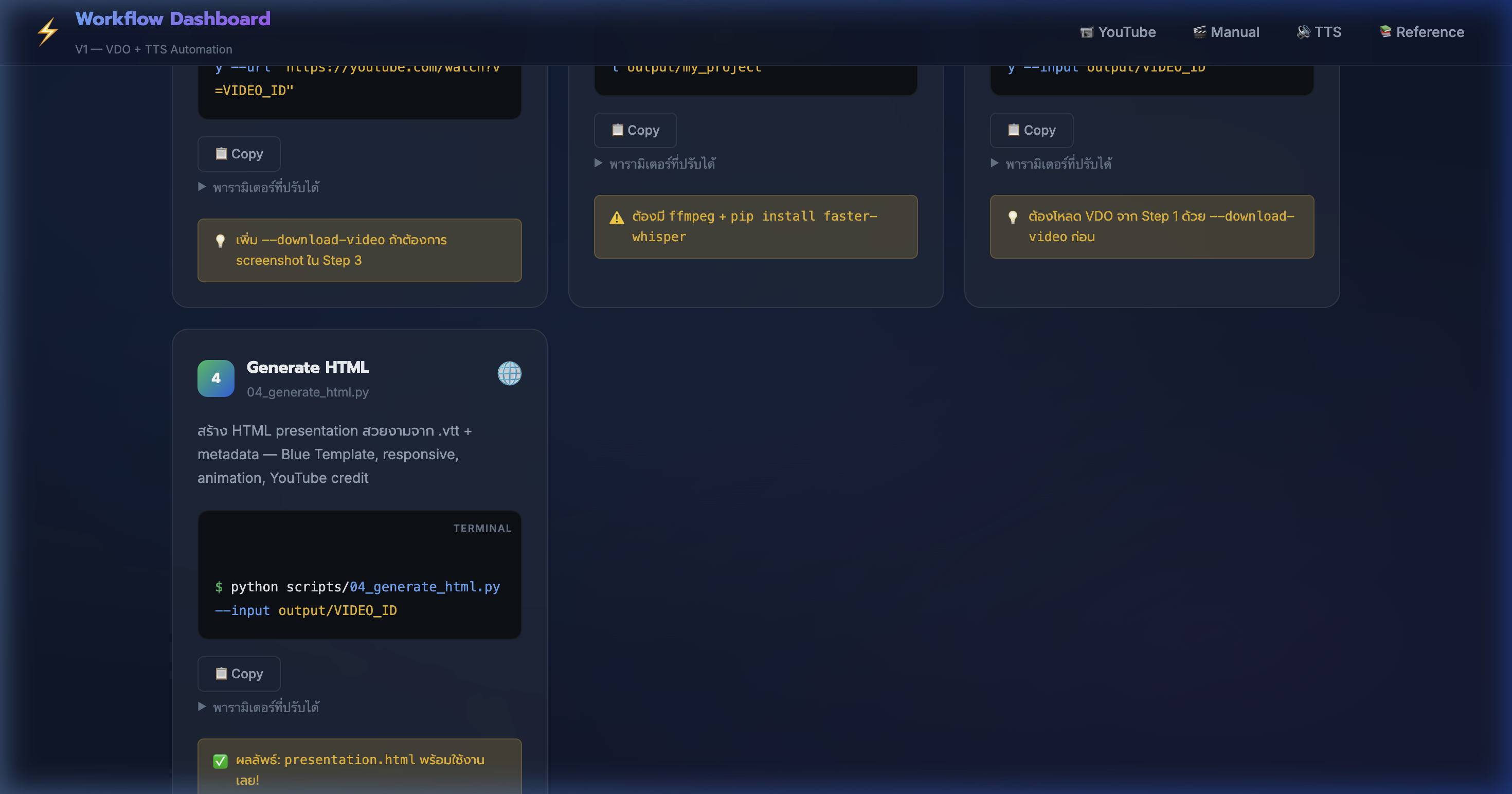
6) YouTube Pipeline — สร้าง HTML Presentation
📍 00:04:25
"สร้าง HTML presentation อัตโนมัติ — Blue Template สวยงาม responsive พร้อม YouTube credit"
 📸 Step 4: Generate HTML ด้วย 04_generate_html.py + ตัวอย่าง output
📸 Step 4: Generate HTML ด้วย 04_generate_html.py + ตัวอย่าง output
📄 Step 4: Generate HTML
- ใช้สคริปต์
python scripts/04_generate_html.py --input output/VIDEO_ID
- Parse .vtt → แบ่งเป็น 12 chapters → ดึง quote + bullet points จาก subtitle text
- ใช้ Blue Template: สี #2563eb gradient, font Prompt, fade-up animation
- ถ้า subtitle มาจาก YouTube → ใส่ YouTube credit box + timestamp links อัตโนมัติ
- มี collapsible transcript — กดดูบท subtitle ทั้งหมดได้
- ผลลัพธ์:
presentation.html — เปิดดูได้เลยไม่ต้องรัน server
- 💡 เพิ่ม
--title ตั้งชื่อ + --chapters 18 เพิ่มจำนวน section ได้
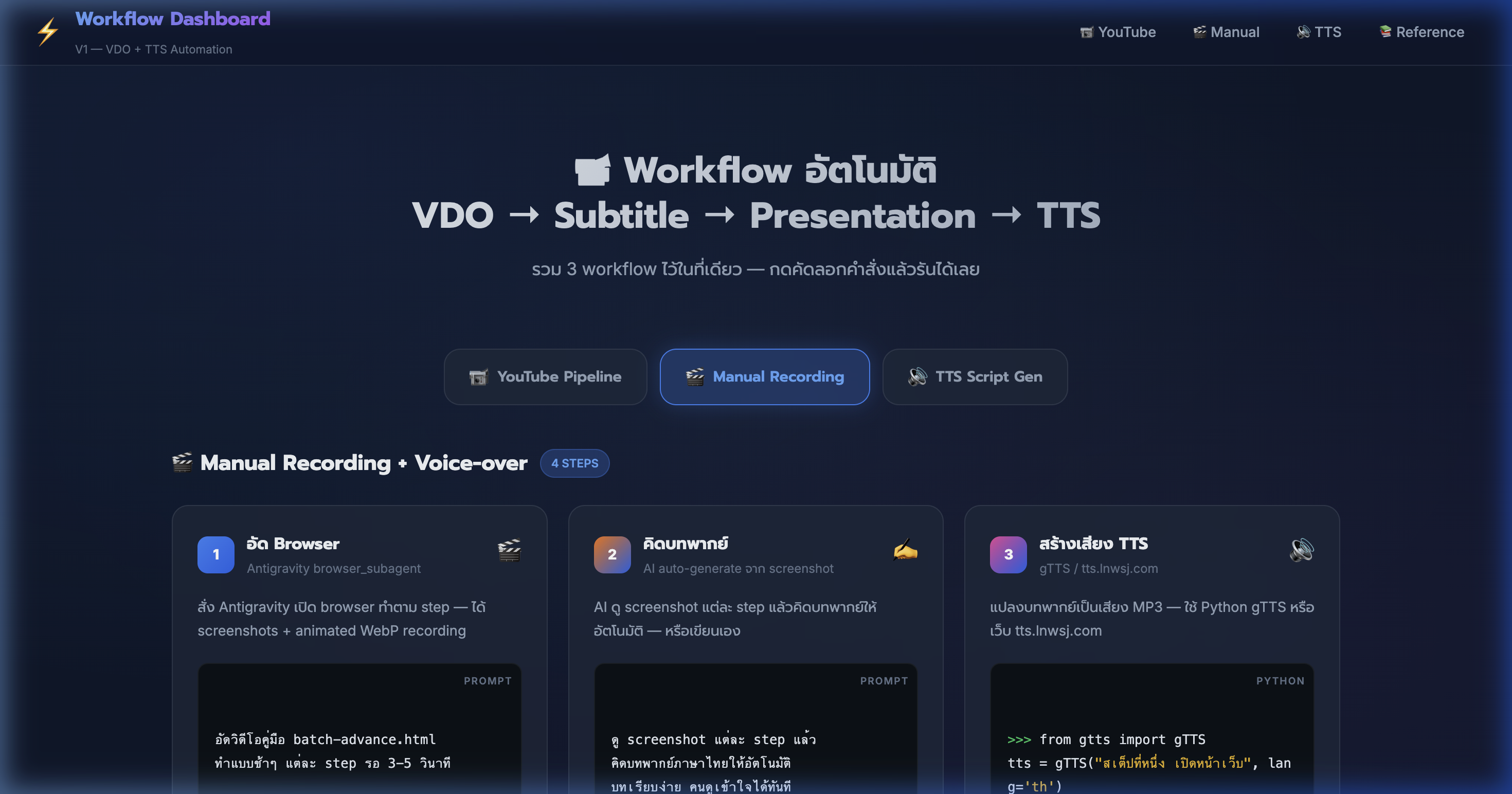
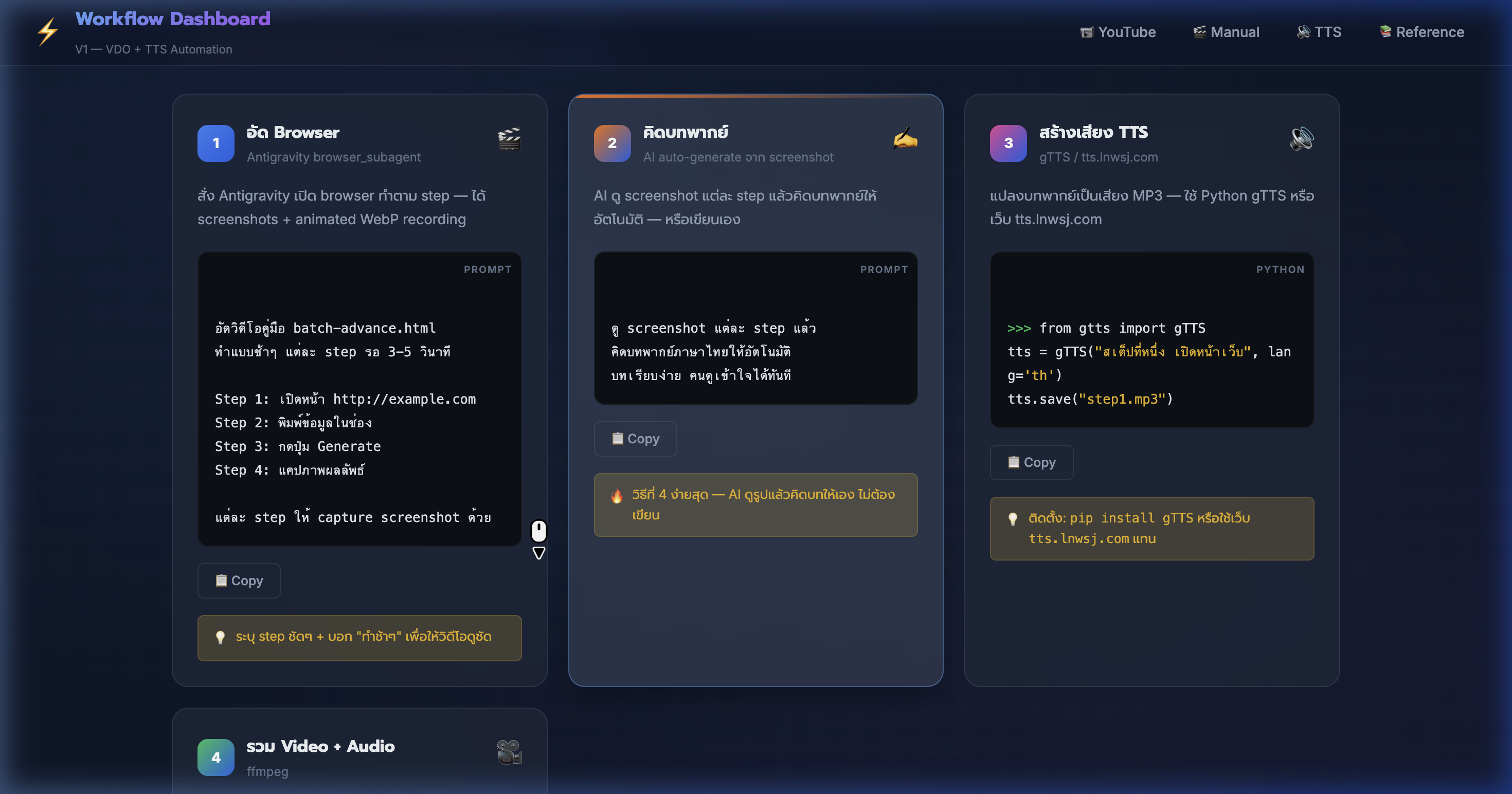
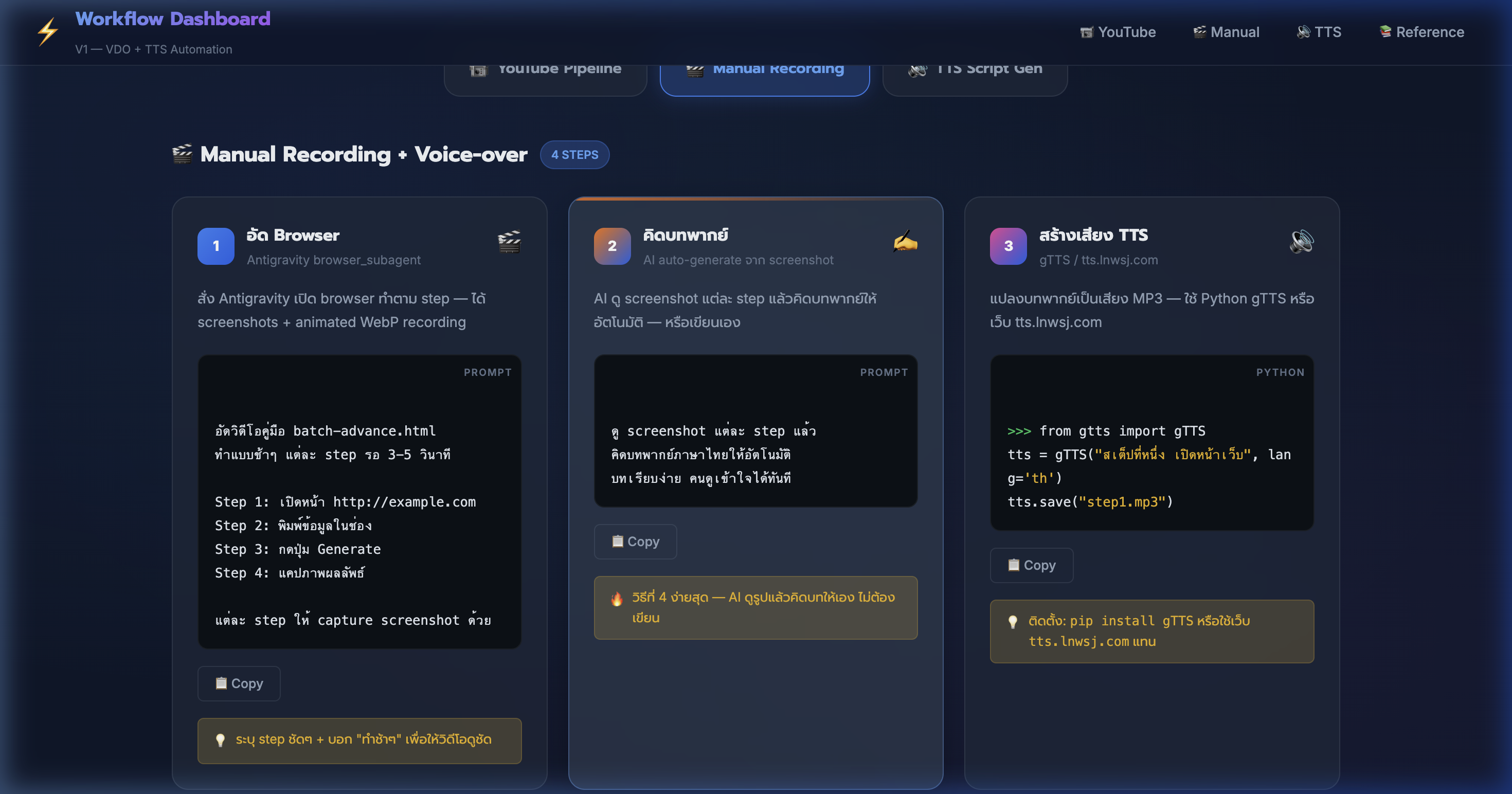
7) Tab 2: Manual Recording — อัด Browser ด้วย Antigravity
📍 00:05:18
"สั่ง Antigravity เปิด browser ทำตาม step — ได้ screenshots + animated WebP recording"
 📸 Manual Recording tab — Step 1: อัด Browser สั่ง Antigravity browser_subagent
📸 Manual Recording tab — Step 1: อัด Browser สั่ง Antigravity browser_subagent
🎬 Manual Step 1: อัดคลิป
- ใช้ Antigravity browser_subagent — สั่ง AI เปิดเว็บแล้วทำ demo อัตโนมัติ
- ระบุ step ชัดๆ เช่น "เปิดหน้า A → กดปุ่ม B → scroll ดู C → จับภาพ"
- ได้ animated WebP recording ทั้งหมด + screenshot แต่ละ step
- สั่ง "wait 3 seconds" ระหว่าง step → คลิปดูชัด ไม่เร็วเกินไป
- recording เป็นไฟล์ .webp — ดูได้บน browser โดยตรง หรือแปลงเป็น MP4
- ตัวอย่าง: อัด WorkflowAppV1 3 tabs → ได้คลิป 11 KB + ภาพ 8 รูป
- 💡 ใส่ RecordingName ให้สื่อความหมาย → หาไฟล์ง่ายทีหลัง
8) Manual Recording — AI คิดบทพากย์
📍 00:06:11
"AI ดู screenshot แต่ละ step แล้วคิดบทพากย์ภาษาไทยให้อัตโนมัติ — ไม่ต้องเขียนเอง"
 📸 Step 2: คิดบทพากย์ — 4 วิธี เขียนเอง / ร่าง+แก้ / keywords / AI อัตโนมัติ
📸 Step 2: คิดบทพากย์ — 4 วิธี เขียนเอง / ร่าง+แก้ / keywords / AI อัตโนมัติ
✍️ Manual Step 2: บทพากย์
- วิธีที่ 1: เขียนบทเอง 100% — ละเอียดสุด แต่ใช้เวลามากที่สุด
- วิธีที่ 2: ร่างบทคร่าวๆ → ให้ AI ขัดเกลา → ตรวจแล้วใช้ได้เลย
- วิธีที่ 3: ใส่ keywords แต่ละ step → AI เขียนบทจาก keyword
- วิธีที่ 4 (แนะนำ): AI ดู screenshot แต่ละ step → คิดบทให้ อัตโนมัติ 100%
- Prompt: "ดู screenshot แล้วคิดบทพากย์ภาษาไทย บทเรียบง่าย คนดูเข้าใจได้ทันที"
- บทควรมีโครงสร้าง: เกริ่น (3 วิ) → อธิบาย step → สรุปสั้น
- 💡 วิธีที่ 4 ง่ายสุด + เร็วสุด — เหมาะกับคนที่ ไม่อยากเขียนบทเอง
9) Manual Recording — สร้างเสียง TTS ด้วย gTTS (Python)
📍 00:07:04
"แปลงบทพากย์เป็น MP3 ด้วย Python gTTS — สั่ง 3 บรรทัด ได้ไฟล์เสียงทันที"
 📸 Step 3A: สร้างเสียง TTS ด้วย Python gTTS — code ตัวอย่าง
📸 Step 3A: สร้างเสียง TTS ด้วย Python gTTS — code ตัวอย่าง
🐍 TTS ด้วย Python
- ติดตั้ง:
pip install gTTS — ใช้ Google Text-to-Speech API ฟรี
- สร้างเสียง:
tts = gTTS('สเตปที่หนึ่ง เปิดหน้าเว็บ', lang='th')
- บันทึก:
tts.save('step1.mp3') — ได้ MP3 ใช้ได้ทันที
- เสียง gTTS เป็น Google voice — ฟังชัด เป็นธรรมชาติ ภาษาไทยดี
- ข้อจำกัด: เสียงเดียว ไม่ปรับโทน + ต้องมี internet ตอน generate
- เหมาะกับทำเร็วๆ ไม่เน้นคุณภาพเสียงสูงมาก — prototype หรือ draft
- 💡 ใช้ gTTS สร้าง draft → ฟังดูก่อน → ถ้าดีใช้เลย ถ้าไม่ดีไปใช้ tts.lnwsj.com
10) Manual Recording — สร้างเสียง TTS ด้วย tts.lnwsj.com
📍 00:07:57
"เว็บ tts.lnwsj.com สร้างเสียง Ai คุณภาพสูง — เลือกเสียงได้หลายแบบ ทั้งชายและหญิง"
 📸 Step 3B: สร้างเสียง TTS ด้วยเว็บ tts.lnwsj.com — หลายเสียง หลาย persona
📸 Step 3B: สร้างเสียง TTS ด้วยเว็บ tts.lnwsj.com — หลายเสียง หลาย persona
🌐 TTS ด้วย tts.lnwsj.com
- เปิดเว็บ tts.lnwsj.com → login ด้วยรหัส 8 หลัก
- ข้อดีกว่า gTTS: เลือกเสียงได้หลายแบบ — ชายทุ้ม หญิงสดใส ชายเร็ว
- สร้างได้หลาย script + หลาย persona พร้อมกัน ใน 1 batch
- ใช้ Gemini 2.5-flash สร้างบท → ได้หลายสไตล์: ป้ายยา / เล่าเรื่อง / Q&A
- เสียงคุณภาพ HD — ฟังธรรมชาติมากกว่า gTTS เหมาะกับ production
- ดาวน์โหลดเป็น ZIP ไฟล์ MP3 พร้อมใช้กับ ffmpeg
- 💡 ถ้าทำ VDO ขายจริง → ใช้ tts.lnwsj.com / ถ้า draft → ใช้ gTTS
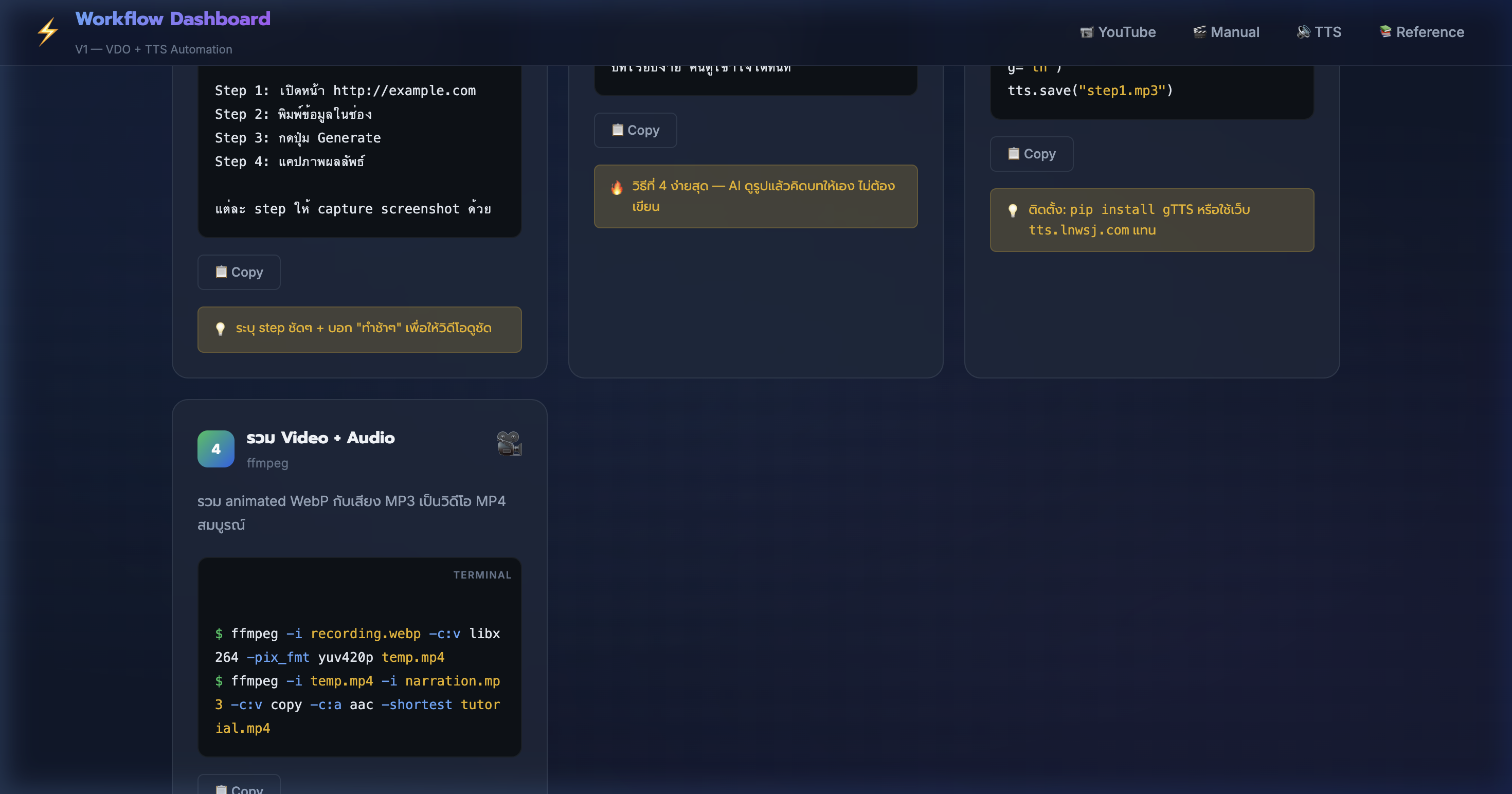
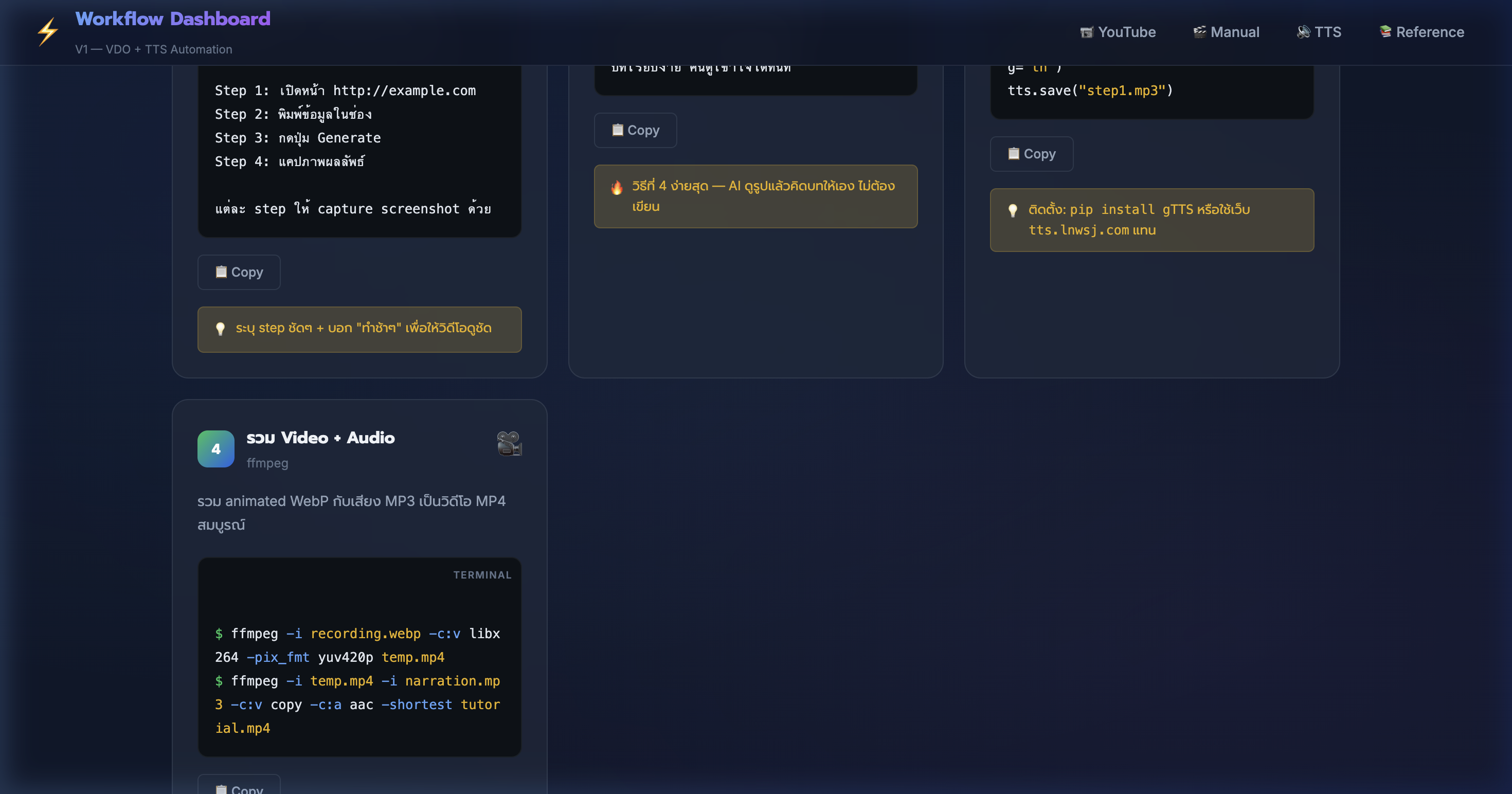
11) Manual Recording — รวม Video + Audio ด้วย ffmpeg
📍 00:08:50
"รวม recording กับเสียงพากย์เป็น MP4 สมบูรณ์ — 2 คำสั่ง ffmpeg จบ"
 📸 Step 4: รวม Video + Audio ด้วย ffmpeg — .webp + .mp3 → .mp4
📸 Step 4: รวม Video + Audio ด้วย ffmpeg — .webp + .mp3 → .mp4
🎞️ Manual Step 4: รวมวิดีโอ
- ขั้นที่ 1: แปลง WebP → MP4:
ffmpeg -i recording.webp -c:v libx264 -pix_fmt yuv420p temp.mp4
- ขั้นที่ 2: รวมเสียง:
ffmpeg -i temp.mp4 -i narration.mp3 -c:v copy -c:a aac -shortest tutorial.mp4
- ใช้
-shortest ตัดให้ video + audio จบพร้อมกัน ไม่ยาวเกิน
- ผลลัพธ์: tutorial.mp4 — วิดีโอคู่มือพร้อมเสียงพากย์ เปิดได้ทุก player
- format MP4 (H.264 + AAC) — รองรับทุก platform ทั้ง YouTube, TikTok, Facebook
- ขนาดไฟล์: video 10 วินาที + audio ~30 วินาที ≈ 2-5 MB
- 💡 เพิ่ม
-vf scale=1920:1080 ปรับ resolution ให้เป็น Full HD
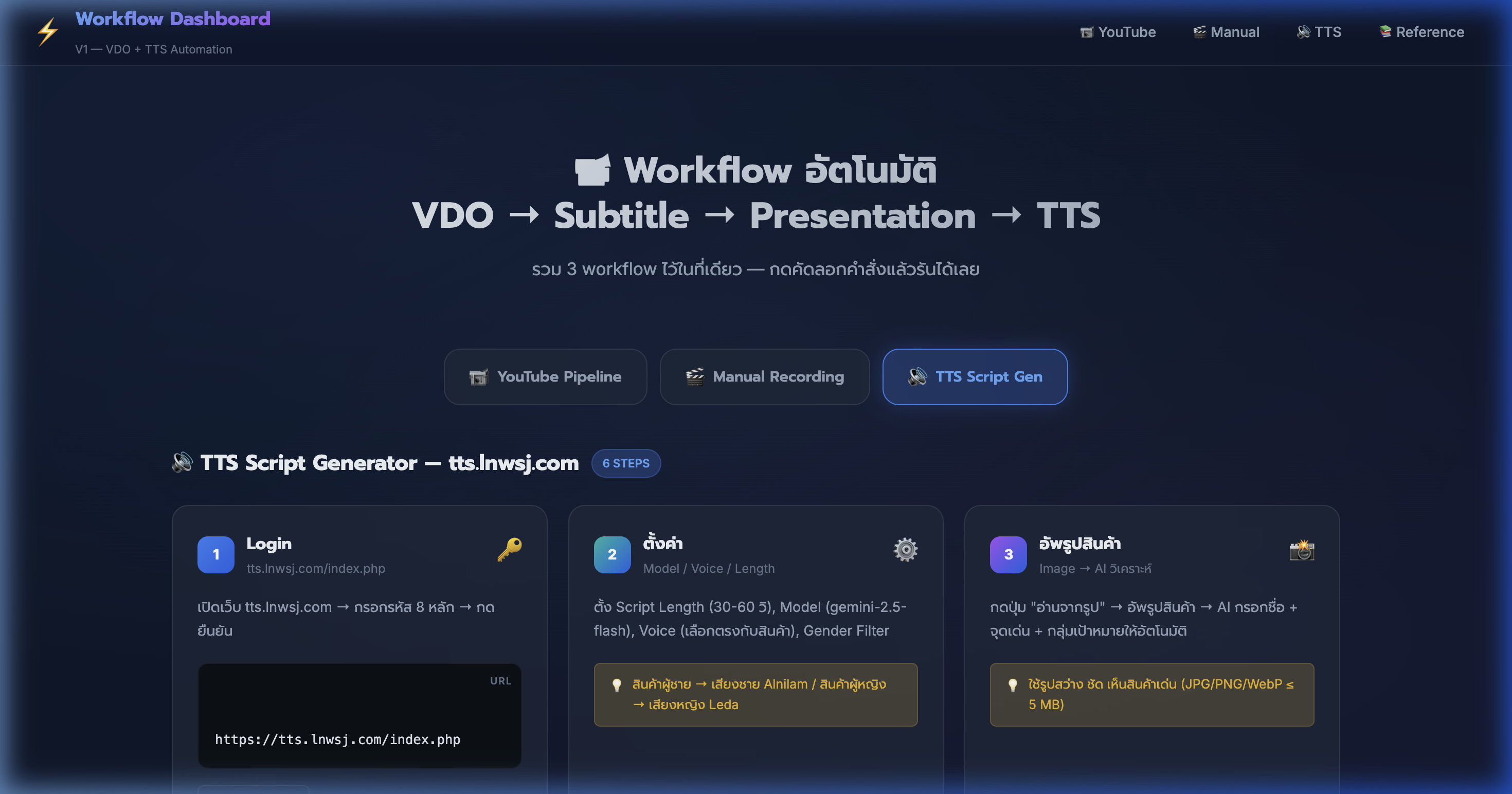
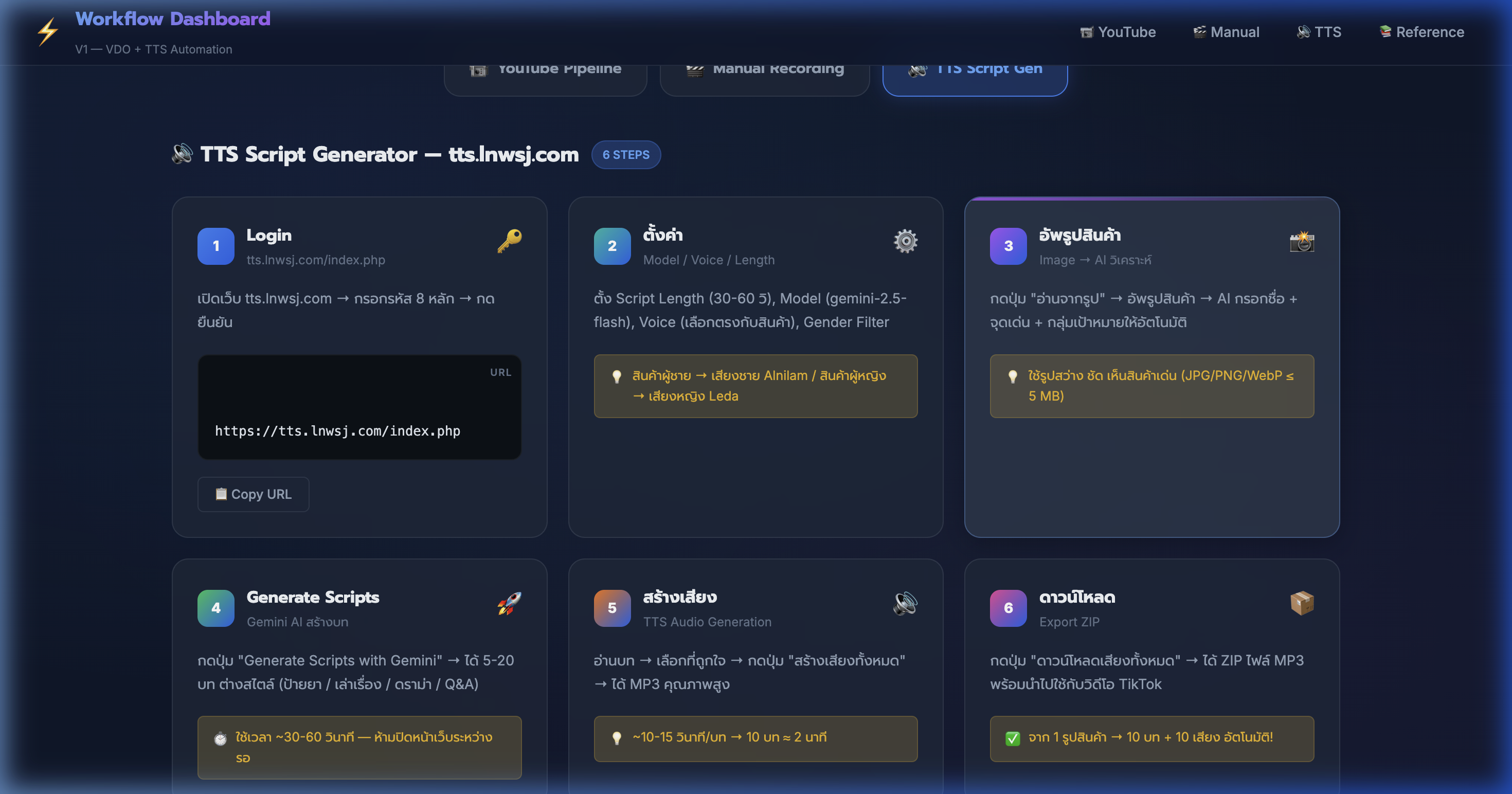
12) Tab 3: TTS Script Gen — Login + ตั้งค่า
📍 00:09:43
"เปิดเว็บ tts.lnwsj.com → ตั้งค่า Model, Voice, Length → พร้อมสร้างบท"
 📸 TTS Script Gen tab — Step 1: Login + Step 2: ตั้งค่า Model/Voice/Length
📸 TTS Script Gen tab — Step 1: Login + Step 2: ตั้งค่า Model/Voice/Length
🔊 TTS Step 1-2: Login + Settings
- Step 1: Login — เปิด tts.lnwsj.com → กรอกรหัส 8 หลัก → กดยืนยัน
- login สำเร็จ → redirect เข้าหน้า Dashboard อัตโนมัติ
- Step 2: ตั้งค่า ใน sidebar ซ้าย — 4 ช่องหลัก
- Script Length: 30-60 วินาที สำหรับ TikTok (ปรับ 2-5 นาทีสำหรับ YouTube ได้)
- Model: gemini-2.5-flash เร็ว + แม่นยำ (หรือ 2.5-pro ถ้าเน้นคุณภาพ)
- Voice: เลือกตามสินค้า — ผู้ชาย → Alnilam / ผู้หญิง → Leda หรือ Aoede
- ⚠️ ห้ามเปลี่ยน settings ระหว่าง generate — รอให้เสร็จก่อนค่อยเปลี่ยน
13) TTS Script Gen — อัพรูปสินค้า + AI วิเคราะห์
📍 00:10:36
"กดปุ่ม อ่านจากรูป → AI วิเคราะห์ภาพ → กรอกชื่อ + จุดเด่น + กลุ่มเป้าหมายให้อัตโนมัติ"
 📸 Step 3: อัพรูปสินค้า → AI กรอกข้อมูลให้ — ชื่อ จุดเด่น 5 ข้อ
📸 Step 3: อัพรูปสินค้า → AI กรอกข้อมูลให้ — ชื่อ จุดเด่น 5 ข้อ
📸 TTS Step 3: อัพรูปสินค้า
- กดปุ่ม "อ่านจากรูป" → เลือกรูปสินค้าจากเครื่อง
- AI วิเคราะห์ภาพ → กรอก ชื่อสินค้า + จุดเด่น 5 ข้อ + กลุ่มเป้าหมาย ให้
- รองรับ JPG, PNG, WebP ขนาดไม่เกิน 5 MB
- ใช้รูป สว่าง ชัด เห็นสินค้าเด่น → AI วิเคราะห์ได้แม่นยำกว่า
- สามารถ แก้ไขข้อมูล ที่ AI กรอกได้ก่อน generate — ปรับให้ตรงใจ
- หรือกรอกข้อมูลเอง: ชื่อ + จุดเด่น 5 ข้อ + กลุ่มเป้าหมาย + ราคา
- 💡 รูปจาก Shopee/Lazada ของสินค้าเราจะได้ข้อมูลตรงที่สุด
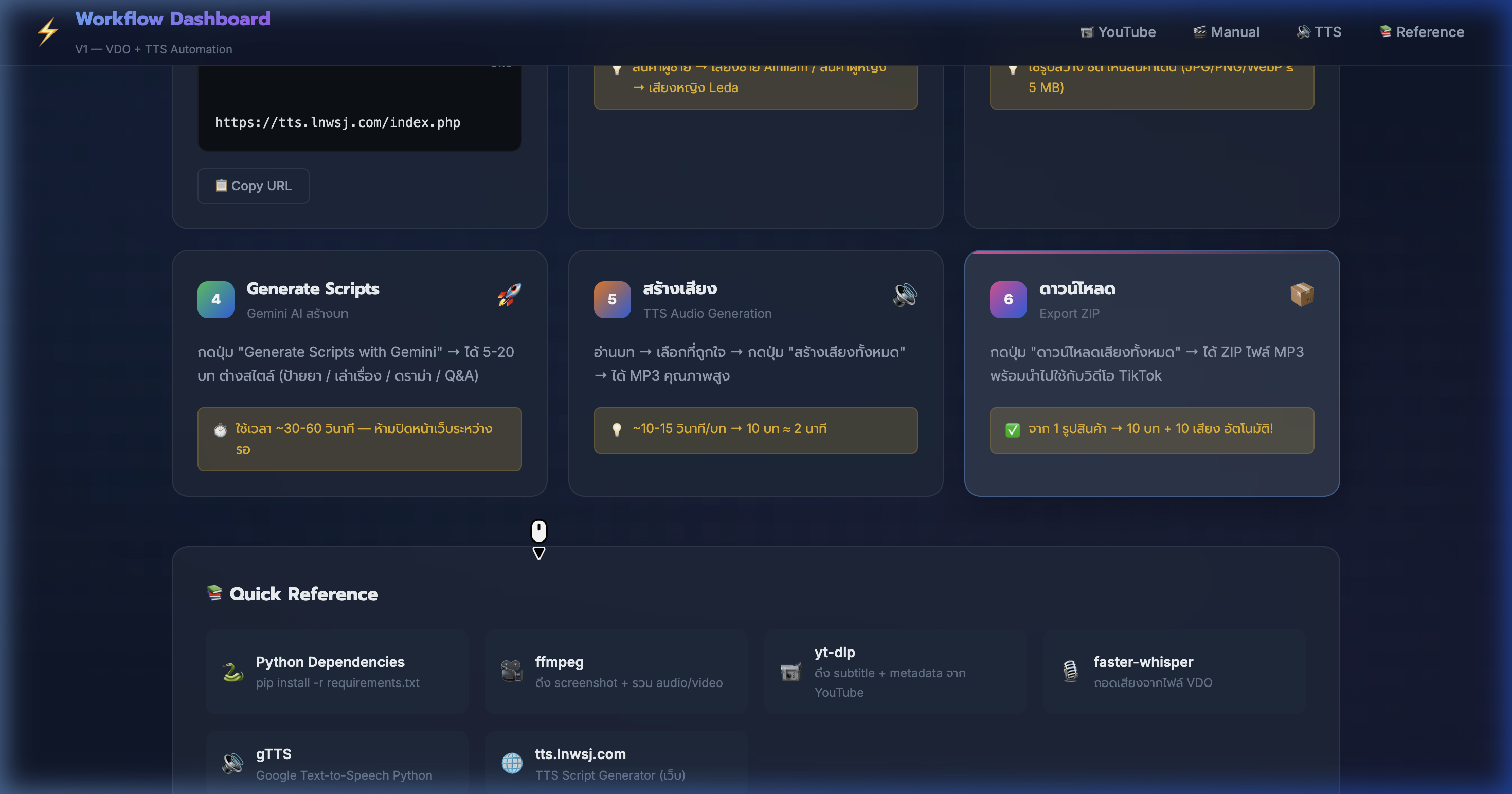
14) TTS Script Gen — Generate Scripts ด้วย Gemini
📍 00:11:29
"กดปุ่ม Generate Scripts with Gemini → รอ 30-60 วินาที → ได้ 5-20 บทต่างสไตล์"
 📸 Step 4: Generate Scripts — กดปุ่มสีเขียว → ได้บทหลายสไตล์
📸 Step 4: Generate Scripts — กดปุ่มสีเขียว → ได้บทหลายสไตล์
🚀 TTS Step 4: Generate บท
- กดปุ่ม "Generate Scripts with Gemini" สีเขียวขนาดใหญ่
- รอ 30-60 วินาที — ระบบแสดง loading spinner ระหว่างรอ
- ได้บท 5-20 ชุด แต่ละชุดมีโทน + มุมนำเสนอไม่ซ้ำกัน
- สไตล์ที่ได้: ป้ายยา ("มาค่ะ ป้ายยาเลย!") / เล่าเรื่อง ("เมื่อวานฉันลอง...") / Q&A / ดราม่า
- แต่ละบทมีโครงสร้างครบ: Hook (3 วิ) → เนื้อหา → CTA
- ⚠️ ห้ามปิดหน้าเว็บ ระหว่างรอ — script จะหายต้อง generate ใหม่
- 💡 สร้าง 10 ตัว → อ่านทุกบท → เลือก 3-5 ตัวที่ Hook ดีที่สุด
15) TTS Script Gen — สร้างเสียง + ดาวน์โหลด
📍 00:12:22
"อ่านบท → เลือกที่ถูกใจ → กดสร้างเสียงทั้งหมด → ดาวน์โหลดเป็น ZIP"
 📸 Step 5-6: สร้างเสียง MP3 + ดาวน์โหลด ZIP — ~10-15 วินาทีต่อบท
📸 Step 5-6: สร้างเสียง MP3 + ดาวน์โหลด ZIP — ~10-15 วินาทีต่อบท
🎵 TTS Step 5-6: เสียง + ดาวน์โหลด
- Step 5: สร้างเสียง — คลิก "สร้างเสียงทั้งหมด" → ระบบ generate MP3 ทีละตัว
- ใช้เวลา ~10-15 วินาทีต่อบท — 10 บท ≈ 2 นาที
- ทุกเสียงใช้ Voice ที่เลือกไว้ — น้ำเสียง + ความเร็วสม่ำเสมอ
- กดปุ่ม ▶ Play ฟัง preview ก่อนดาวน์โหลดได้
- Step 6: ดาวน์โหลด — กด "ดาวน์โหลดเสียงทั้งหมด" → ได้ ZIP ไฟล์ MP3
- ผลลัพธ์: จาก 1 รูปสินค้า → 10 บท + 10 เสียง อัตโนมัติ!
- 💡 นำ MP3 ไปรวมกับ VDO ตัดต่อได้เลยใน EP 50001 (ตัดต่อ SJ88)
16) Quick Reference — เครื่องมือที่ต้องติดตั้ง
📍 00:13:15
"ทุกเครื่องมือรวมไว้ในหน้าเดียว — ดูง่าย ไม่ต้องจำ กดลิงก์ไปเลย"
 📸 Quick Reference Grid แสดง 6 เครื่องมือสำคัญ + วิธีติดตั้ง
📸 Quick Reference Grid แสดง 6 เครื่องมือสำคัญ + วิธีติดตั้ง
📚 เครื่องมือสำคัญ
- Python —
pip install -r requirements.txt ติดตั้ง dependencies ทั้งหมด
- ffmpeg — ดึง screenshot จาก VDO + รวม audio/video → ติดตั้งจาก ffmpeg.org
- yt-dlp — ดึง subtitle + metadata จาก YouTube:
pip install yt-dlp
- faster-whisper — ถอดเสียงจากไฟล์ VDO:
pip install faster-whisper
- gTTS — Google Text-to-Speech สำหรับ Python:
pip install gTTS
- tts.lnwsj.com — เว็บ TTS Script Generator สร้างบท + เสียง Ai คุณภาพสูง
- 💡 ติดตั้งทุกอย่างรวดเดียว:
pip install yt-dlp faster-whisper gTTS
17) เปรียบเทียบ 3 Workflow — เมื่อไหร่ใช้อะไร
📍 00:14:08
"มี YouTube URL ใช้ Pipeline 1 / ต้องอัดเอง ใช้ Manual / ขายของ TikTok ใช้ TTS"
 📸 ตารางเปรียบเทียบ 3 workflows — YouTube vs Manual vs TTS
📸 ตารางเปรียบเทียบ 3 workflows — YouTube vs Manual vs TTS
🔀 เลือก Workflow ที่ใช่
- YouTube Pipeline: มี YouTube URL อยู่แล้ว → ดึง subtitle → สร้าง HTML อัตโนมัติ (เร็วสุด)
- Manual Recording: ต้องอัดเอง (สาธิตซอฟต์แวร์ ทำคู่มือ) → ได้คลิป + เสียงพากย์ (ยืดหยุ่นสุด)
- TTS Script Gen: ขายของ TikTok → อัพรูป 1 รูป → ได้ 10 บท + เสียง (สำหรับขายของ)
- ใช้ ร่วมกันได้: ดึง subtitle จาก YouTube → สร้าง HTML → แล้วอัดเสียงพากย์ทับ
- ทุก workflow ผลลัพธ์สุดท้ายคือ: HTML presentation + VDO + เสียงพากย์
- เรียงความง่าย: TTS Script Gen (ง่ายสุด) → YouTube Pipeline → Manual Recording (ต้องทำมากสุด)
- 💡 มือใหม่ → เริ่มจาก TTS Script Gen ก่อน → ค่อยลอง Manual Recording
18) สรุปและขั้นตอนถัดไป
📍 00:15:01
"Workflow Dashboard V1 ให้คุณทำทุกอย่างได้ในหน้าเดียว — กดคัดลอก แล้วสร้างผลงานได้เลย"
 📸 สรุปทั้ง 3 workflow + ลิงก์ไป EP ถัดไป
📸 สรุปทั้ง 3 workflow + ลิงก์ไป EP ถัดไป
📦 สรุปทั้งหมด
- YouTube Pipeline: URL → subtitle → screenshot → HTML (4 steps, 3 scripts)
- Manual Recording: อัด browser → บทพากย์ → TTS → MP4 (4 steps, 1 recording)
- TTS Script Gen: รูป 1 ใบ → 10 บท + 10 เสียง (6 steps, เว็บ tts.lnwsj.com)
- ทุกคำสั่งกดปุ่ม 📋 Copy ใน Dashboard → paste ใน terminal → รัน
- เปิดดู Dashboard:
open WorkflowAppV1/index.html
- ขั้นตอนถัดไป: EP 20001 สร้าง VDO ด้วย App Desktop + Google Flow
- 💡 ลองทำจริงตามแต่ละ tab → จะเข้าใจ workflow ทั้งระบบ
📝 หมายเหตุ: เนื้อหาสรุปจากวิดีโอคอร์สติ๊กต๊อก 2026